

Introduction
Machine learning algorithms are rules that allow computers to learn from data without requiring external code or programming. These algorithms identify data, predict patterns, and improve performance by enhancing datasets. It improves their learning automatically through their experience. The three main categories of machine learning algorithms are supervised, unsupervised, and reinforcement learning. Each category has its distinct purpose in various applications.
In 2025, Machine learning algorithms will be an emerging technology widely necessitated across numerous sectors. They play a crucial role in innovation, intelligence, and data-driven efficiency in many sectors. There is an outbreak in the growth of data generation and the integration of AI in daily life. This creates the demand for intelligent systems to learn automatically from the generated data to process and derive insights. From personalized e-commerce platforms to enhanced healthcare systems, these algorithms optimize the supply chain and detect fraudulent activities.
This article is useful for tech aspirants, data scientists, AI professionals, and business leaders who want to understand the impact of machine learning algorithms on daily life. Anyone curious about this algorithm gets comprehensive resources to master the evolving landscape. To stay ahead in today’s technologically driven landscape, this article on the fundamental building blocks of artificial intelligence is your stepping stone.
Understanding Machine learning Algorithms types
Machine learning algorithms are classified into three types, each developed for distinct problems and data according to industry needs.
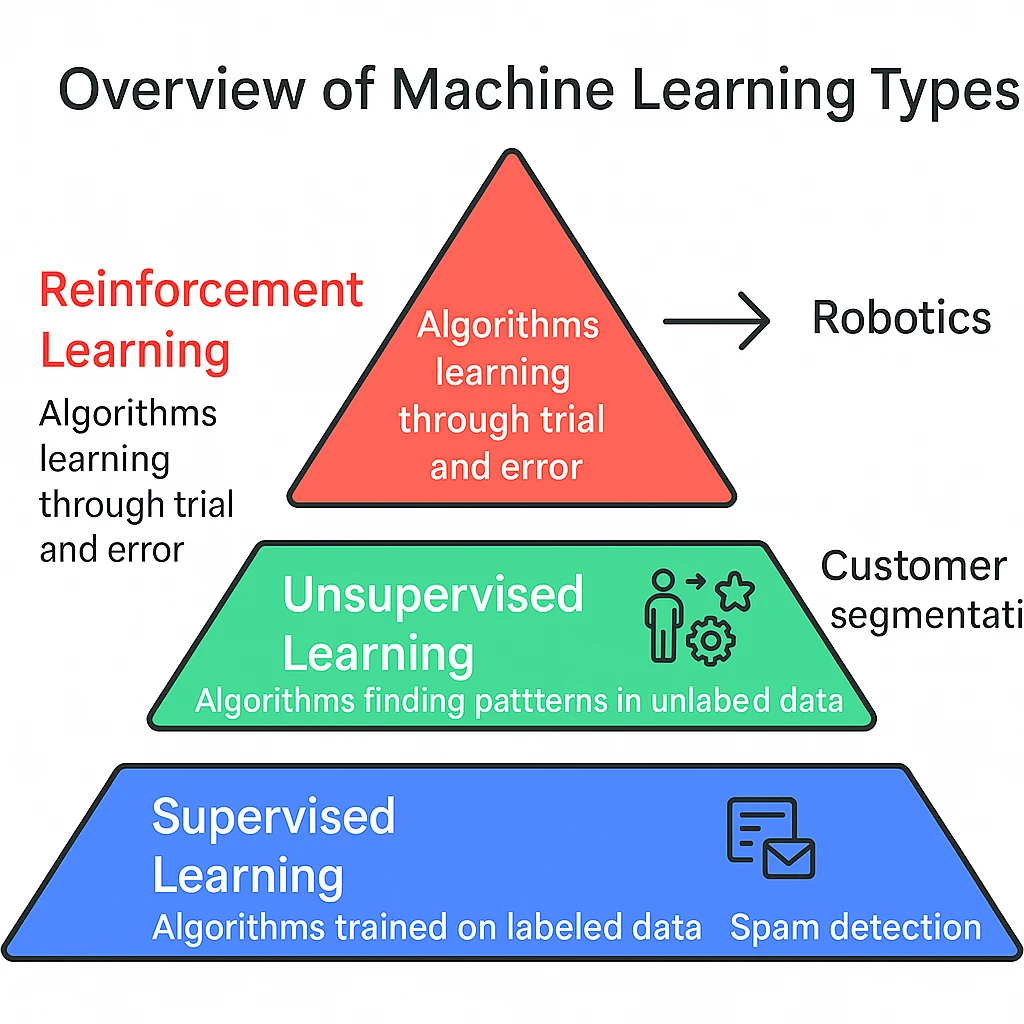
Supervised Learning Algorithms
These algorithms use labeled dataset to train the system model. Here, each input data point is paired with the corresponding output, helping the system predict the output based on the input data. Some of the commonly used supervised learning algorithms are decision trees, linear regression, support vector machines (SVM), and logistic regression. They are mainly used in applications that involve spam or fraud detection, medical diagnosis, image recognition, and speech recognition.
Unsupervised Learning Algorithms
This differs from supervised learning algorithms, which rely on labeled datasets. This algorithm mainly focuses on hidden patterns, intrinsic structures, or relationships within the data. Some unsupervised learning methods are k-means clustering, principal component analysis (PCA), hierarchical clustering, and generative adversarial networks(GANs). These methods are widely used in applications that require anomaly detection, customer segmentation, dimensionality reduction, clustering, recommendation systems, and cybersecurity.
Reinforcement Learning Algorithms
This algorithm works by involving an agent that learns to communicate with the environment, make decisions by performing some actions, and receive feedback in the form of penalties or rewards. Based on this analysis, the system model changes its behavior accordingly, improving the strategies based on feedback or rewards.
Some of the key reinforcement techniques are Q-learning, policy gradient methods, and deep Q-networks(DQN). This technology has real-time applications in robotics, game design, autonomous cars, treatment plans based on individual characteristics and responses, and traffic light control. In 2025, research is primarily concentrated on improving the efficiency and stability of RL in complex real-world scenarios.
To select the convenient machine learning algorithm for particular tasks, understanding these algorithms is significant to ensure skilled solutions.
Criteria for Selecting the Right Algorithm
Selecting the appropriate algorithm criteria is a challenging step in training new system models. Some of the significant steps are as follows.
Data Type and Problem Complexity
A thorough understanding of the data is the key to choosing the correct algorithm. This may involve identifying the type of data, such as textual, time series, numerical or categorical labelled or unlabelled dataset, linear or nonlinear regression models, structured or unstructured data, such as image or text, patterns, and volume, which has a major impact on the right algorithm selection. This method also effectively captures the underlying patterns.
The complexity of the problem is based on categories such as classification, reinforcement learning, regression, dimensionality, or clustering. Higher complexity may require intricate algorithms to predict sophisticated patterns, whereas simpler problems require simple algorithms to detect data patterns.
Interpretability vs. Accuracy
There is always a trade-off between the interpretability of an algorithm with its predictive accuracy. Some of the industrial sectors, like healthcare and finance, use algorithmic models like decision trees and logistic regression, which offer better transparency. Thus, interpretability makes us understand the importance of regulatory compliance before making a decision.
In contrast, black box algorithms such as deep learning models like Convolutional Neural Network may result in higher accuracy at the cost of interpretability. Thus the choice of interpretability vs accuracy highly depends on the specific system models and the need for explainability.
Computational Resources
Computational resources are another critical factor, as they depend on application models. Some algorithms, like deep learning models such as neural networks, support vector machines, and ensemble methods, require significant processing power and memory. Thus, they demand strong processing capabilities. Some lesser models, like linear regression or k-nearest neighbors, may require limited resources. Evaluating the computation cost from the training and implementing the model is a considerable factor to ensure profitability within the infrastructure.
Real World Constraints
Real-world constraints may include the required speed of prediction and scalability. For instance, fraud detection models require fast and efficient models, whereas large-scale data processing may require scalable algorithms. Understanding model decisions plays a significant role in predicting the theoretical capabilities of the algorithm, given the demand of intended real-time applications. Balancing all the above factors may ensure that the accurate system model development aligns with the project’s specific goal.
Top 10 must-know Machine learning Algorithms for 2025
The 10 essential machine learning algorithms to know in 2025, along with their core concepts and key use cases, are as follows:
1. Linear Regression
Linear regression uses straight-line equations to model the relationship between dependent and independent variables for trend analysis. Key use cases include sales forecasting based on past trends, predicting housing prices, stock prices, risk assessments, and patient recovery times.
2. Logistic Regression
This uses a sigmoid function to predict the feasibility of binary classification tasks between 0 and 1. Key use cases are medical diagnosis, fraud detection, spam detection, and customer churn prediction.
3. Decision trees
Data is partitioned into subsets like a tree branch based on features to make predictions. This handles classification (labelled or unlabelled data) and regression tasks. Key use cases include customized treatment plans, customer segmentation, predicting equipment failure, credit scoring models, and product recommendation systems.
4. Random Forest
This method develops multiple decision trees and estimates the mean prediction across various individual trees to improve accuracy and reduce overfitting. Key use cases include spam detection, predicting complex transaction patterns, detecting network incursions, and predicting customer purchase patterns in retail shops.
5. Support Vector Machines (SVM)
SVM finds optimal boundaries to classify data points between classes. This it is used for nonlinear data.
Key use cases: Facial recognition, image classification, spam filtering, protein classification, handwriting analysis, sentiment analysis.
6. K-Nearest Neighbors (KNN)
This classifies the data based on most of the k classes near the training data. It groups similar data close to each other, which requires no training phase. This makes it flexible and easily understood.Key use cases: Customer segmentation for customized marketing strategies, image recognition, anomaly detection, and recommendation systems.
7. K-Means Clustering
This is an unsupervised algorithm where data are partitioned into predefined clusters based on feature similarity. Key use cases include categorizing user behavior patterns in social media, customer segmentation, pattern recognition, Network anomaly detection, and identifying customers with similar purchasing patterns.
8. Gradient Boosting Machines
Some models, such as XGBoost, LightGBM, and Naive Bayes, use these models to build algorithms that correct errors from previous errors to achieve high predictive performance. Key use cases: Text classification and Medical analysis, spam filtering, ranking problems, and financial forecasting.
9. Neural Networks
This method is inspired by the structure of the human brain. It consists of neural networks with interconnected nodes formed in layers. The network learns patterns by adjusting the node connections. Key use cases: Deep learning neural network, machine translation, self driving, image and speech recognition like Siri, Alexa, MRI, and CT scan images for health diagnosis.
10. Reinforcement Learning
This learning algorithm uses rewards and penalties for previous decision-making. It analyzes this feedback to train AI agents with optimal use-case strategies: AI opponents play in video games, Movement control in robotics automation, game development, and Stock optimization using trading strategies. Professionals should have knowledge about these algorithms to apply the most appropriate methods for the specific system model in real-time applications. This improves the efficiency of the model.
Table 1: Comparison Table of 10 Algorithms
| Algorithm | Learning Type | Strengths | Raw implementation | Interpretability | Normalization |
| Linear Regression | Supervised | Simple and fast | Easy | High | Yes, needed |
| Logistic Regression | Supervised | Binary classification | Easy | High | No |
| Decision trees | Supervised | Both Numerical and Categorical data. | Easy | High | No |
| Random Forest | Supervised | Minimizes Overfitting in case of large datasets | Medium | Medium | Yes, needed |
| Support Vector Machines (SVM) | Supervised | High dimensional spaces | Medium | High | No |
| K-Nearest Neighbors (KNN) | Supervised | Non parametric | Difficult | High | No |
| K-Means Clustering | unsupervised | Scalable | Medium | Medium | Yes, needed |
| Gradient Boosting Machines | Supervised | High predictive performance | Very Difficult | Medium | Yes, needed |
| Neural Networks | Supervised | Complex patterns identification | VeryDifficult | Low | Yes, needed |
| Reinforcement Learning | Reinforcement | Optimal actions over time | VeryDifficult | Low | Yes |
Real-world Applications and Industry Use Cases
The following are some key applications and use cases in healthcare, finance, marketing and e-commerce, and autonomous systems.
Healthcare
Machine learning provides better and faster advancements in personalized medicine and patient monitoring. MRI and CT scan images use these algorithms to analyze disease. Cardiovascular risk factors, such as retinal images, can be predicted with the help of deep learning algorithms. Machine learning is also used to identify and develop new drugs by predicting how molecules will inreact with them. It is beneficial in new contagious diseases.
Finance
In the financial sector, ML is used to analyse stock optimization using trading strategies. It helps to personalize banking services based on customer needs. Fraud detection is predicted with the help of customer regular transaction patterns. This helps in major economic threats and protects the customer from fraudulent activities. Some robo advisors use machine learning algorithms to provide personalized investment strategies to optimize portfolio management.
Marketing and E-commerce
Machine learning algorithms predict user purchase patterns, pricing strategies, sales, and demand forecasting techniques. They generate leads and turn them into customers by sending product recommendations. They also assist in adjusting prices based on competition and market factors.
Autonomous Systems
Robotic games, AI opponent-player games, and drones use these machine learning algorithms to navigate automation techniques. Self-driving cars utilize this learning to perceive their environment and make driving decisions. Ships and other maritime vessels use this learning technology to avoid collisions and provide route maps. Thus, it acts as an advanced driver assistance system.
Emerging Trends in Machine Learning Algorithms (2025 & Beyond)
In 2025, Machine learning algorithms will experience higher advancements by introducing several emerging trends across real-time applications.
Deep Learning Integration
Integrating deep learning algorithms with machine learning technology improves accuracy in results like image and speech recognition, with the model’s training to process complex data structures.
Automated Machine Learning (AutoML)
This learning helps to simplify the model training for automating tasks like hyperparameter tuning and feature selection, making the machine more feasible for non-experts.
Explainable AI (XAI)
It assures ethical concern, addresses, and transparency in making decisions. This provides insights into model decisions.
Federated Learning
This allows the model to be trained across collaborative models without centralizing data, which addresses the dataset’s privacy concerns.
Low Code/No Code ML
Recent advancements in machine learning algorithms show that fully operational businesses can be developed with the help of these technologies, without requiring any coding skills. This helps startups empower non-experts to build ML applications.
What to Learn Next
Recent transformative advancements in machine learning technology introduce emerging trends in deep learning integration, automated machine learning, and low-code/no-code platforms. To navigate this evolving technology, it is necessary to utilize tools like Scikit-learn and TensorFlow. These tools provide more datasets for developing new ML models.
Professionals should learn advanced courses through Tutedude platforms, which offer courses from foundational to expert-level skills. After gaining theoretical knowledge,it is advisable to gain practical knowledge through hands-on projects.
Conclusion
2025 is the year for machine learning technology to evolve fast. Whether you are new or skilled, now is the time to act. It is more recommended to explore real-world projects, master emerging tools, and stay with the trend. Tutedude offers a better course to turn your curiosity into career-ready skills.



